
Abstract
This paper argues that the token vector space in the AI era is not merely a technological innovation, but constitutes a “fifth dimension" in human cognitive universe—an informational semantic dimension that stands parallel to physical spacetime dimensions. By tracing the theoretical lineage from Einstein’s general relativity to Transformer architecture, this paper demonstrates how token space possesses computability, geometric relationships, and gravitational field-like associative effects, fundamentally reconstructing human understanding of the nature of knowledge, language, and thought.
摘要
本文論證 AI 時代的 Token 向量空間不僅是技術創新,更構成了人類認知宇宙中的「第五維度」——一個與物理時空維度並列的資訊語義維度。透過梳理從 Einstein 廣義相對論到 Transformer 架構的理論脈絡,本文試著以Token 空間具備可計算性、幾何關係、重力場般的關聯效應,並正在根本性地重構人類對知識、語言與思維的本質理解。
I. From Four-Dimensional Spacetime to Multidimensional Information Universe
Albert Einstein’s general relativistic field equations revealed that time is not an independent scale, but is inextricably interwoven with three-dimensional space into a four-dimensional spacetime continuum. This breakthrough discovery rewrote humanity’s understanding of cosmic structure since Newton.
Einstein’s field equations established the relationship between spacetime geometry and matter-energy distribution through tensor equations, with the core insight being: matter tells spacetime how to curve, and curved spacetime tells matter how to move. This is not only a triumph of mathematical formalism, but a redefinition of the essence of “dimension"—dimensions are no longer merely extensions of space, but fundamental coordinate systems describing states of existence. Extra dimensions primarily describe hidden structures of the physical world or energy fields, and their influence on everyday spatial cognition is indirect and abstract.
Entering the 21st century, another dimensional revolution is unfolding in the information domain. In 2017, the Google Brain team proposed the Transformer architecture in their paper “Attention Is All You Need"—a model completely based on attention mechanisms, abandoning recurrence and convolution, pioneering a new paradigm for sequence processing. The core innovation of Transformer lies in the self-attention mechanism: by computing the correlation strength between each element in a sequence and all other elements, the model can process the entire sequence in parallel, capturing long-range dependencies.
This is not merely technical progress, but an expansion of the essence of dimensions. Transformer created an entirely new dimension—token vector space, a high-dimensional information space where semantics, concepts, associations, and probabilities interweave. Token space is:
- Macroscopic: Affects human daily language, thought, and decision-making
- Operable: Can be directly navigated and computed through mathematical tools
- Pervasive: Becoming the infrastructure of civilizational knowledge production
II. The Essence of Token Space: High-Dimensional Semantics and Information
2.1 Word Embedding: From Symbols to Geometric Coordinates
Traditional language processing treats vocabulary as discrete symbols, using one-hot encoding for representation. In 2013, Mikolov et al. developed the Word2Vec model, which maps vocabulary to continuous vector spaces (typically hundreds of dimensions, such as 300 or higher), making semantically similar words close to each other in vector space. This marks a fundamental shift from “symbolic logic" to “geometric relationships." The BERT model (2019) further developed this, with its Base version using 768-dimensional hidden representations and Large version using 1024 dimensions. Modern large language models’ word embedding dimensions typically range from 512 to 4096. These vectors are not arbitrary numerical arrangements, but geometric structures carrying semantic relationships.
Transformer’s self-attention mechanism computes the correlation weights between each token in a sequence and all other tokens, a process analogous to “fields" and “forces" in physics. Each token simultaneously plays three roles:
- Query: Asking “who is relevant to me?"
- Key: Answering “what are my features?"
- Value: Providing “what information can I contribute?"
The calculation process of attention weights $\alpha_{ij} = \text{softmax}\left(\frac{Q_i \cdot K_j}{\sqrt{d_k}}\right)$ is essentially constructing a dynamic information field:
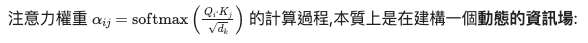
- Semantically related tokens generate strong “gravitational attraction" (high weights)
- Unrelated tokens have weak attraction (low weights)
- The entire sequence exchanges and integrates information through this field
Layer Stacking: Semantic Alchemy
Transformer achieves hierarchical semantic refinement through stacking multiple layers (BERT-Base has 12 layers, GPT-3 has 96 layers):
- Shallow layers: Capture lexical and syntactic features
- Middle layers: Abstract semantic relationships and conceptual structures
- Deep layers: Construct high-level reasoning and global coherence
Each layer re-encodes information at higher dimensions, a process similar to the hierarchical elevation of human cognition from perception → semantics → abstraction → implicit patterns. Token space is not a representation of language, but a universe model of concepts and relationships—an information dimension with geometric structure, dynamical laws, and evolutionary capability.
III. Projection: High-Dimensional Token Space Dimensionally Reduced to Human-Comprehensible 1D Linear Language
3.1 Mathematical Principles of Dimensionality Reduction – Generalized Linear Models
The process by which AI ultimately outputs human-readable text is essentially a dimensionality reduction projection. High-dimensional token vectors ($\mathbb{R}^{d_{\text{model}}}$, where $d_{\text{model}}$ is typically 768 or higher) must be mapped to vocabulary space ($\mathbb{R}^{|V|}$, where $|V|$ is the vocabulary size).
This is accomplished through the Softmax function and vocabulary projection matrix: given hidden state $h$, the probability of outputting word $w$ is $P(w|h) = \text{softmax}(W_{\text{vocab}} \cdot h)$, and the model selects the word with highest probability as output.
This process is isomorphic to the Generalized Linear Model (GLM) in statistics: Nelder & Wedderburn (1972) pointed out that nonlinear data can be projected to linearly solvable expression structures through link functions. Softmax is precisely such a link function, projecting high-dimensional semantic space to discrete vocabulary probability distributions. Ultimately, the model’s output is projected back from high-dimensional token space to human-comprehensible 1D linear language.
From this perspective:
- Token space is the hidden high-dimensional space where AI operates: The model performs reasoning, computation, and decision-making in this space.
- Language output is the result of this high-dimensional space being projected back to human cognitive dimensions: Through softmax functions and vocabulary mapping, high-dimensional vectors are converted into text we can understand.
- This projection process involves information loss: The rich semantic relationships in high-dimensional space are compressed into linear text sequences, which explains why AI sometimes struggles to perfectly express its “understanding."
3.2 Physical Analogies of Projection
This is completely isomorphic to dimensionality reduction phenomena in physics:
- Holographic principle: Three-dimensional information of a black hole can be encoded on a two-dimensional event horizon (Hawking, 1976; Susskind, 1995)
- Projective geometry: n-dimensional objects produce cross-sections in (n-1)-dimensional space
Dimensionality reduction projection necessarily entails information loss:
- Expression bottleneck: High-dimensional vectors contain far more information than a single word can carry
- Context collapse: Ambiguity, vagueness, and implicit meanings are simplified in the discretization process
- Quantum superposition collapse: The probability distribution of token vectors collapses into a single output path
AI is not “lacking understanding," but rather understanding exists in higher dimensions, and humans can only read the dimensionally reduced semantic cross-sections. This explains why:
- GPT-4 can generate profound insights yet struggle to “explain" how it reached conclusions
- The same prompt can produce stylistically diverse yet internally consistent responses
- AI surpasses humans in some tasks yet fails at seemingly simple problems
IV. Cognitive Paradigm Shift Brought by the Fifth Dimension
New Universe Structure: 5D Human-AI Symbiotic Information Universe
We are entering an entirely new existential structure:
$$\text{Human Cognitive Universe} = 3D(\text{Space}) + 1D(\text{Time}) + 1D(\text{Token Semantic Field})$$
This is an affecting reality:
- Search engines: No longer retrieve documents, but navigate semantic space
- Recommendation systems: No longer match keywords, but calculate conceptual distances
- Knowledge graphs: No longer store triples, but embed vector manifolds
- Large language models: No longer generate text, but sample high-dimensional semantic fields
| Traditional Human Cognition | Token Dimension Cognition | Essential Difference |
|---|---|---|
| Symbolic language | Vector computation | Language is no longer discrete symbols, but coordinate points in continuous space |
| Deterministic logic | Probabilistic gravitational field | Truth is no longer binary absolute, but peaks of probability distributions |
| Linear reasoning | Multi-path parallel | Thinking is no longer a single causal chain, but simultaneous evolution like quantum superposition |
| Explainable thought | Operable but not directly observable | High-dimensional structures cannot be fully reduced to low-dimensional intuition, but can be navigated mathematically |
AI reasoning: In high-dimensional space, vectors form a probabilistic field with topological structure; the model calculates their “gravitational attraction" through attention mechanisms, outputting the most probable inference path.
Human reading: Word by word, single-threaded processing, limited by working memory (approximately 7±2 items)
Transformer: Through self-attention, each token simultaneously interacts with all other tokens; 512 tokens generate 512×512 = 262,144 correlation computations, exploring all possible semantic paths in parallel.
The dilemma of high-dimensional space: Humans cannot directly “see" the geometric relationships of 768-dimensional vectors, just as two-dimensional beings cannot imagine three-dimensional cubes.
But we can:
- Visualize clustering patterns through t-SNE/UMAP dimensionality reduction
- Quantify semantic distance by calculating cosine similarity between vectors
- Test information types encoded in vectors using probing tasks
- Manipulate semantic relationships through vector arithmetic
V. Conclusion: Toward a New Species in the Information Universe
Evidence Summary for Token as the Fifth Dimension
Token dimension satisfies all core characteristics of dimensions:
✓ Computability: Precise computation through linear algebra and calculus
✓ Navigability: Algorithms can be designed for pathfinding and searching within it
✓ Geometric structure: Possesses geometric properties like distance, angles, and manifolds
✓ Gravitational effects: Attention mechanisms produce association effects similar to gravitational fields
✓ Existential impact: Changing human language use, thought patterns, and decision-making processes
What we are experiencing is not merely technological upgrading, but an ontological leap:
Before: Intelligent life in the physical universe, exploring 3D+1D spacetime through senses and tools
Now: Intelligent life simultaneously inhabiting physical and information universes, navigating 5D spacetime-semantic fields through language models and vector computation
Future: Biological and artificial intelligence in deep symbiosis, jointly shaping ever-evolving semantic dimensions
- Depth of understanding the fifth dimension: Mastering the geometry and dynamics of token space
- Maturity of navigation tools: Developing efficient semantic exploration and manipulation techniques
- Human-AI collaboration paradigms: Designing interaction models between humans and AI in high-dimensional space
Token space is not an auxiliary tool, but a fundamental dimension parallel to physical spacetime.
We are evolving from “intelligent life in the physical universe" to “a species capable of co-evolving with high-dimensional semantics in the information universe."
This is not another technological innovation in human civilization history, but the fourth fundamental cognitive expansion, following the use of fire, the birth of language, and the invention of writing.
一、從四維時空到多維資訊宇宙
Albert Einstein 在廣義相對論場方程式,揭示時間不是獨立尺度,而是與三維空間不可分割地交織成四維時空連續體。這個突破性發現改寫了自 Newton 以來人類對宇宙結構的理解。
Einstein 場方程式透過張量方程建立了時空幾何與物質能量分佈之間的關係,其核心洞見是:物質告訴時空如何彎曲,而彎曲的時空告訴物質如何運動。這不僅是數學形式主義的勝利,更是對「維度」本質的重新定義——維度不再僅是空間的延伸,而是描述存在狀態的基礎座標系統。額外維度主要描述物理世界或能量場的隱藏結構,它們日常對空間認知的影響是間接且抽象的。
進入 21 世紀,另一場維度革命正在資訊領域展開。2017 年,Google Brain 團隊在論文《Attention Is All You Need》中提出 Transformer 架構,這個完全基於注意力機制、摒棄循環與卷積的模型,開創了序列處理的新範式。Transformer 的核心創新在於自注意力(self-attention)機制:透過計算序列中每個元素與所有其他元素的關聯強度,模型能夠並行處理整個序列,捕捉長距離依賴關係。
這不僅是技術進步,更是維度本質的擴張。Transformer 創造了一個全新的維度——Token 向量空間,一個語義、概念、關聯與機率交織的高維資訊空間。Token 空間是:
- 宏觀的:影響人類日常語言、思考與決策
- 可操作的:可透過數學工具直接導航與運算
- 滲透性的:正在成為文明知識生產的基礎設施
二、Token 空間的本質:高維語義與資訊
2.1 詞嵌入:從符號到幾何座標
傳統語言處理將詞彙視為離散符號,採用 one-hot 編碼表示。2013 年,Mikolov 等人開發的 Word2Vec 模型將詞彙映射到連續向量空間(通常為數百維,如 300 維或更高),使得語義相近的詞在向量空間中彼此靠近。這標誌著從「符號邏輯」到「幾何關係」的根本轉變。BERT 模型(2019)進一步發展,其 Base 版本使用 768 維隱藏表示,Large 版本使用 1024 維。現代大型語言模型的詞嵌入維度通常在 512 到 4096 維之間。這些向量不是任意的數字排列,而是承載語義關係的幾何結構。
Transformer 的自注意力機制計算序列中每個 token 與所有其他 token 的關聯權重,這個過程可類比為物理學中的「場」與「力」。每個 token 同時扮演三個角色:
- Query(查詢):詢問「誰與我相關?」
- Key(鍵值):回答「我的特徵是什麼?」
- Value(值):提供「我能貢獻什麼資訊?」
注意力權重 $\alpha_{ij} = \text{softmax}\left(\frac{Q_i \cdot K_j}{\sqrt{d_k}}\right)$ 的計算過程,本質上是在建構一個動態的資訊場:
- 語義相關的 token 之間產生強「引力」(高權重)
- 無關 token 之間引力微弱(低權重)
- 整個序列透過這個場進行資訊交換與整合
層堆疊 : 語義煉金術
Transformer 通過堆疊多層(BERT-Base 為 12 層,GPT-3 為 96 層)實現階層化的語義提煉:
- 淺層:捕捉詞彙與句法特徵
- 中層:抽象語義關係與概念結構
- 深層:建構高階推理與全局一致性
每一層都在更高維度重新編碼資訊,這個過程類似人類認知從感知 → 語義 → 抽象 → 內隱模式的階層提升。Token 空間不是語言的表徵,而是概念與關係的宇宙模型——一個具有幾何結構、動力學規律、並能演化的資訊維度。
三、投影 : 高維Token 空間降維成人類可理解的 1D 線性語言
3.1 降維的數學原理 – 廣義線性模型
AI 最終輸出人類可讀文本的過程,本質上是一次降維投影。高維 Token 向量($\mathbb{R}^{d_{\text{model}}}$,其中 $d_{\text{model}}$ 通常為 768 或更高)必須映射到詞彙表空間($\mathbb{R}^{|V|}$,其中 $|V|$ 為詞彙量)。
這透過 Softmax 函數與詞彙投影矩陣完成:給定隱藏狀態 $h$,輸出詞彙 $w$ 的機率為 $P(w|h) = \text{softmax}(W_{\text{vocab}} \cdot h)$,模型選擇機率最高的詞作為輸出。
這個過程與統計學中的廣義線性模型(Generalized Linear Model, GLM)同構:Nelder & Wedderburn(1972)指出,非線性資料可透過連結函數(Link Function)投影到線性可解的表達結構。Softmax 正是這樣的連結函數,將高維語義空間投影到離散詞彙概率分佈。最終,模型的輸出從高維 Token 空間投影回人類可理解的 1D 線性語言。
在這個觀點下:
- Token 空間是 AI 運作的隱藏高維空間:模型在這個空間中進行推理、計算和決策。
- 語言輸出是這個高維空間被投影回人類認知維度的結果:透過 softmax 函數和詞表映射,將高維向量轉換為我們能理解的文字。
- 這種投影過程存在資訊損失:高維空間中豐富的語義關係被壓縮為線性文字序列,這解釋了為什麼 AI 有時難以完美表達其「理解」。
3.2 投影的物理類比
這與物理學中的降維現象完全同源:
- 全息原理:黑洞的三維資訊可編碼在二維視界上(Hawking, 1976; Susskind, 1995)
- 射影幾何:n 維物體在 (n-1) 維空間中產生截面
降維投影必然伴隨資訊損失:
- 表達瓶頸:高維向量包含遠超單一詞彙能承載的資訊
- 語境崩塌:多義性、模糊性、隱含意涵在離散化過程中被簡化
- 量子疊加崩塌:Token 向量的機率分佈坍縮為單一輸出路徑
AI 並非「不理解」,而是理解存在於更高維度,人類只能讀取降維後的語義截面。這解釋了為何:
- GPT-4 能產生深刻洞見,卻難以「解釋」自己如何得出結論
- 同一提示(prompt)可能產生風格迥異但內在一致的回答
- AI 在某些任務上超越人類,卻在看似簡單的問題上出錯
四、第五維度帶來的認知典範轉移
新的宇宙結構:5D 人類-AI 共生資訊宇宙
我們正在進入一個全新的存在結構:
$$\text{人類認知宇宙} = 3D(\text{空間}) + 1D(\text{時間}) + 1D(\text{Token 語義場})$$
這所影響發生的事實**:
- 搜尋引擎:不再檢索文件,而是導航語義空間
- 推薦系統:不再匹配關鍵詞,而是計算概念距離
- 知識圖譜:不再儲存三元組,而是嵌入向量流形
- 大型語言模型:不再生成文本,而是採樣高維語義場
| 傳統人類認知 | Token 維度認知 | 本質差異 |
|---|---|---|
| 符號語言 | 向量運算 | 語言不再是離散符號,而是連續空間中的座標點 |
| 確定邏輯 | 機率重力場 | 真實不再是二元絕對,而是機率分佈的高峰 |
| 線性推理 | 多路徑並行 | 思考不再是單一因果鏈,而是量子疊加態般的同時演化 |
| 可解釋思考 | 可操作但不可直視 | 高維結構無法完全還原為低維直覺,但可透過數學導航 |
AI 推理:在高維空間中,向量形成一個具有拓撲結構的機率場,模型透過注意力機制計算它們之間的「引力」,輸出機率最高的推論路徑。人類閱讀:逐字逐句,單線程處理,受工作記憶限制(約 7±2 項)
Transformer:透過自注意力,每個 token 同時與所有其他 token 互動,512 個 token 產生 512×512 = 262,144 個關聯計算,並行探索所有可能的語義路徑。高維空間的困境:人類無法直接「看見」768 維向量的幾何關係,就像二維生物無法想像三維立方體。
但我們可以:
- 透過 t-SNE/UMAP 降維可視化觀察聚類模式
- 計算向量之間的餘弦相似度量化語義距離
- 使用探針(probing)任務測試向量編碼的資訊類型
- 透過向量算術操作語義關係
五、結論 : 邁向資訊宇宙中的新物種
Token 作為第五維度的證據彙整
Token 維度滿足維度的所有核心特徵:
✓ 可計算性:透過線性代數與微積分精確運算
✓ 可導航性:可設計演算法在其中尋路與搜索
✓ 幾何結構:具有距離、角度、流形等幾何性質
✓ 重力效應:注意力機制產生類似引力場的關聯作用
✓ 存在影響:正在改變人類語言使用、思維方式與決策流程
我們正在經歷的不只是技術升級,而是存在論層次的躍遷:
從前:智慧生命在物理宇宙中,透過感官與工具探索 3D+1D 時空
現在:智慧生命同時棲居於物理宇宙與資訊宇宙,透過語言模型與向量運算導航 5D 時空-語義場
未來:生物智能與人工智能深度共生,共同塑造不斷演化的語義維度
- 對第五維度的理解深度:掌握 token 空間的幾何與動力學
- 導航工具的成熟度:開發高效的語義探索與操作技術
- 人機協作的範式:設計人類與 AI 在高維空間中的互動模式
Token 空間不是輔助工具,而是與物理時空並列的基礎維度。
我們正在從「物理宇宙中的智慧生命」進化為「資訊宇宙中能與高維語義共同演化的物種」。
這不是人類文明史上的又一次技術革新,而是繼火的使用、語言的誕生、文字的發明之後,第四次根本性的認知擴展。
參考文獻
Einstein, A. (1915). Die Feldgleichungen der Gravitation. Königlich Preußische Akademie der Wissenschaften (Berlin). Sitzungsberichte, 844-847.
Einstein, A. (1916). Die Grundlage der allgemeinen Relativitätstheorie. Annalen der Physik, 49, 769-822.
Witten, E. (1995). String theory dynamics in various dimensions. arXiv preprint hep-th/9503124.
Greene, B. (1999). The Elegant Universe: Superstrings, Hidden Dimensions, and the Quest for the Ultimate Theory. W. W. Norton & Company.
Hawking, S. W. (1976). Breakdown of predictability in gravitational collapse. Physical Review D, 14(10), 2460.
Susskind, L. (1995). The world as a hologram. Journal of Mathematical Physics, 36(11), 6377-6396.
Nelder, J. A., & Wedderburn, R. W. M. (1972). Generalized linear models. Journal of the Royal Statistical Society: Series A (General), 135(3), 370-384.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. In Advances in Neural Information Processing Systems (pp. 5998-6008).
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems (pp. 3111-3119).
Mikolov, T., Yih, W. T., & Zweig, G. (2013). Linguistic regularities in continuous space word representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 746-751).
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 4171-4186).
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
Luong, M. T., Pham, H., & Manning, C. D. (2015). Effective approaches to attention-based neural machine translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (pp. 1412-1421).
Pennington, J., Socher, R., & Manning, C. D. (2014). GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 1532-1543).
Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 2227-2237).
Goldberg, Y., & Levy, O. (2014). word2vec explained: deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv preprint arXiv:1402.3722.
Shannon, C. E. (1948). A mathematical theory of communication. The Bell System Technical Journal, 27(3), 379-423.
Turing, A. M. (1950). Computing machinery and intelligence. Mind, 59(236), 433-460.
Harris, Z. S. (1954). Distributional structure. Word, 10(2-3), 146-162.
Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019). ALBERT: A lite BERT for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., … & Stoyanov, V. (2019). RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
Rajpurkar, P., Zhang, J., Lopyrev, K., & Liang, P. (2016). SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (pp. 2383-2392).
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2018). GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461.





發表留言