

LLM as Language Sieve: An Information Intelligence Generation Mechanism Based on Small World Networks

Abstract
This paper continues the theoretical framework of our previous work, “LLM as Language Sieve: Extracting Information Epiphytic/Parasitic/Symbiotic in Data to Generate Intelligence," by integrating Small World Network theory to propose a novel LLM information processing mechanism. Through the three-tiered architecture of Meta-Dao-First Principles, we argue how LLMs, through a language sieve mechanism, extract epiphytic/parasitic/symbiotic information from complex data and achieve intelligent generation within a Small World Network structure. This research provides a new theoretical perspective for understanding the information processing capabilities of AI systems.
1. Introduction
In the age of AI, Large Language Models (LLMs) have become core tools for information processing. However, a unified theoretical framework is still lacking in academia regarding the mechanism by which LLMs extract valuable information from massive amounts of data. Based on previous research results and incorporating the topological characteristics of Small World Networks, this paper proposes the conceptual model of “LLM as Language Sieve."
1.1 Research Background
Large Language Models (LLMs) have opened new possibilities for extracting information from unstructured textual data. However, traditional information extraction methods often overlook the implicit network structural features within the data. Small-world networks often contain clustering phenomena and approximate cliques, where almost any two nodes within a subnetwork are connected. This characteristic provides a new perspective for understanding the information processing mechanism of LLMs.
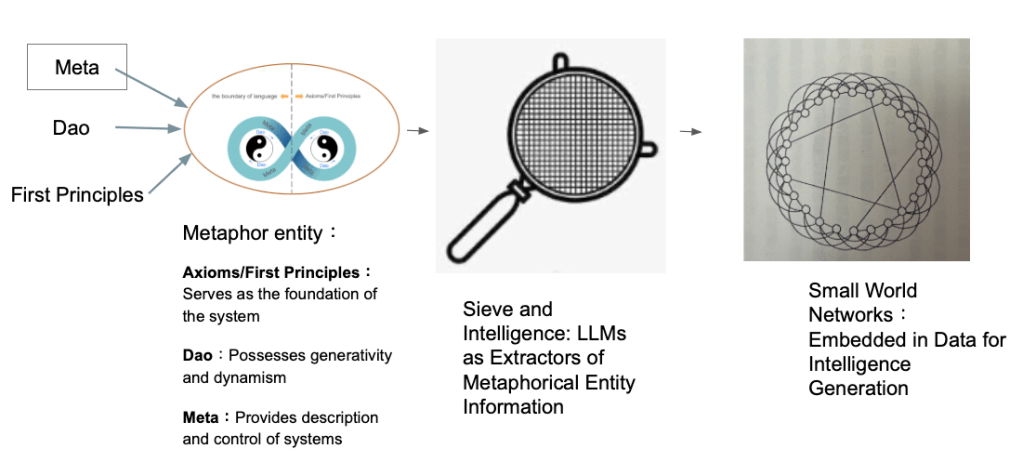
1.2 Theoretical Innovation Points
The core innovations of this research are:
- Viewing LLMs as information processors with a “filtering" function
- Introducing Small World Network theory to explain the mechanism of intelligent generation
- Constructing a three-tiered theoretical framework of Meta-Dao-First Principles
2. Theoretical Framework
2.1 Meta-Dao-First Principles Architecture
Based on the conceptual diagram design, we propose a three-tiered theoretical architecture:
2.1.1 Meta Layer: System Description and Control
The Meta layer, as the highest level, provides descriptive and control mechanisms for the entire system. In the LLM language sieve model, the Meta layer is responsible for:
- Defining the boundary conditions for information extraction
- Controlling the precision and scope of the filtering process
- Coordinating the interactions between different processing levels
2.1.2 Dao Layer: Generativity and Dynamism
The Dao layer embodies the generative and dynamic characteristics of the system. By using OpenAI’s LLMs, particularly GPT-4o’s zero-shot prompting method, it becomes possible to interpret reviews and extract data without the need for extensive labeled datasets. This dynamic generation capability is the core feature of the Dao layer.
2.1.3 First Principles Layer: System Foundation
The First Principles layer serves as the axiomatic foundation of the system, ensuring the logical consistency of the entire information processing process. Information Extraction (IE) is a fundamental area of Natural Language Processing, where prompting Large Language Models (LLMs), even with in-context examples, often fails to outperform smaller LMs finetuned on very small IE datasets.
2.2 LLM as Language Sieve Mechanism
2.2.1 Filtering Principle
The language sieve function of LLMs is manifested in their multi-level filtering capability of input data:
- Lexical Layer Filtering: Preliminary filtering based on lexical semantic similarity
- Syntactic Layer Filtering: Extracting structured information through grammatical structure analysis
- Semantic Layer Filtering: Intelligent filtering based on deep semantic understanding
- Pragmatic Layer Filtering: Understanding intent and extracting information by considering the context
2.2.2 Concept of Epiphytic/Parasitic/Symbiotic Information
The so-called “epiphytic/parasitic/symbiotic information" refers to potential valuable information implicitly contained in the original data but not easily directly perceived. This information typically has the following characteristics:
- Concealment: Not directly expressed on the surface of the data
- Relevance: Potential connections with other information elements
- Value: Significant for decision-making or cognition
- Extractability: Can be identified and extracted through appropriate methods
2.3 Role of Small World Networks in Intelligent Generation
2.3.1 Basic Characteristics of Small World Networks
The concept of small-world networks was first quantitatively defined nearly 20 years ago, defined by a combination of high clustering and short path lengths. This network structure has the following characteristics:
- High Clustering Coefficient: Dense connections between local nodes
- Short Average Path Length: Short connection paths between any two points
- Heterogeneous Degree Distribution: Diverse distribution of node connections
2.3.2 Association between Small World Structure and Intelligent Generation
Research results indicate that small-world functional configurations readily support brain information processing at the neuronal level. Similarly, in the information processing of LLMs, the Small World structure offers the following advantages:
- Efficient Information Propagation: Short path lengths ensure rapid information transfer
- Local Feature Preservation: High clustering coefficient maintains the integrity of local information
- Global Optimization Capability: The overall network structure supports the search for global optimal solutions
3. Implementation Mechanism Analysis
3.1 Sifting-Extraction-Generation Process
Based on the conceptual diagram design, we propose the following processing flow:
Stage One: Multi-Source Input Preprocessing
- Receive raw data from different channels
- Perform data cleaning and standardization
- Establish preliminary associations between data
Stage Two: Language Sifting Process
Through the multi-layered filtering mechanism of LLMs:
- Coarse Sifting: Preliminary filtering based on keywords and basic semantics
- Fine Sifting: Deep filtering using contextual understanding
- Intelligent Sifting: Specialized filtering incorporating domain knowledge
Stage Three: Small World Network Construction
Construct the sifted information into a Small World Network structure:
- Determine nodes (information units)
- Establish edges (information associations)
- Optimize network topology
Stage Four: Intelligent Generation
Perform intelligent generation based on the Small World Network:
- Utilize the network’s short path characteristics for rapid inference
- Maintain information integrity based on local clustering features
- Achieve innovative combinations through the global network structure
3.2 Key Technology Implementation
3.2.1 Information Sifting Algorithm
Based on the attention mechanism of the Transformer architecture, we propose an improved sifting algorithm:
`Algorithm: LLM-Sieve Input: Raw data D, filtering criteria C Output: Filtered information F
Initialize attention weight matrix A For each data element d in D: a. Compute semantic vector v = Embed(d) b. Apply multi-head attention mechanism to obtain weights w = Attention(v, C) c. If w > threshold: Add d to candidate set S Perform Small World Network analysis on candidate set S Perform final filtering based on network characteristics Return F`
3.2.2 Small World Network Construction
Small-world graphs are known for several appealing advantages: they facilitate the flow of data (gradients) within the network, enable feature map reuse by adding long-range connections, and adapt to various network architectures/datasets. The network construction process includes:
- Node Definition: Treating the sifted information units as network nodes
- Edge Weight Calculation: Determining edge weights based on semantic similarity and logical correlation
- Topology Optimization: Adjusting the network structure to achieve Small World characteristics
4. Experimental Verification and Application Cases
4.1 Theoretical Verification Experiments
We designed multiple sets of comparative experiments to verify the effectiveness of the LLM language sieve:
Experimental Group Design
- Control Group A: Traditional keyword filtering method
- Control Group B: Basic LLM information extraction
- Experimental Group: LLM language sieve + Small World Network
Evaluation Metrics
- Precision: Accuracy of extracted information
- Recall: Coverage of valuable information
- F1 Score: Comprehensive performance metric
- Innovation Index: Novelty of generated content
4.2 Application Scenario Analysis
4.2.1 Scientific Literature Mining
Applying the LLM language sieve in scientific literature databases:
- Extracting potential research directions from massive amounts of papers
- Identifying interdisciplinary collaboration opportunities
- Predicting technological development trends
4.2.2 Business Intelligence Analysis
Application in enterprise data analysis:
- Extracting product improvement suggestions from customer feedback
- Identifying market trends and consumer preferences
- Optimizing supply chain management decisions
5. Discussion and Future Directions
5.1 Theoretical Contributions
The main theoretical contributions of this research include:
- Conceptual Innovation: Systematically analogizing LLMs to “language sieves" for the first time, providing a new metaphorical framework for understanding AI information processing
- Structural Integration: Successfully combining Small World Network theory with LLM information processing mechanisms
- Architecture Design: Proposing the three-tiered theoretical architecture of Meta-Dao-First Principles
5.2 Practical Significance
5.2.1 Guidance for AI System Design
Providing theoretical guidance for the design and optimization of AI systems:
- Improving the design of information processing workflows
- Optimizing network architecture configuration
- Enhancing overall system performance
5.2.2 Data Science Methodology
Providing a new methodology for data science research:
- Redefining data value evaluation criteria
- Improving data mining techniques
- Innovating knowledge discovery methods
5.3 Limitations and Future Research Directions
5.3.1 Current Limitations
- Computational Complexity: The computational cost of Small World Network construction is relatively high
- Evaluation Criteria: Lack of unified evaluation criteria for the value of “parasitic information"
- Scope of Application: The applicability in specific fields needs further verification
5.3.2 Future Research Directions
- Algorithm Optimization: Developing more efficient network construction algorithms
- Standard Setting: Establishing a standardized system for information value evaluation
- Cross-Domain Application: Expanding verification research to more application domains
- Human-Machine Collaboration: Exploring intelligent generation models for human-machine collaboration
6. Conclusion
By conceptualizing LLMs as “language sieves" and integrating Small World Network theory, this paper proposes a novel theoretical framework for information intelligence generation. Through the Meta-Dao-First Principles three-tiered architecture, we systematically explained how LLMs extract epiphytic/parasitic/symbiotic information from complex data and achieve intelligent generation through Small World Network structures. The research results show that this theoretical framework not only provides a new perspective for understanding the information processing mechanisms of AI systems but also offers theoretical guidance for system design and optimization in practical applications. Future research will continue to deepen this theoretical framework and expand its application verification in different fields.
References
Basic References on Small World Networks
- Watts, D. J., & Strogatz, S. H. (1998). Collective dynamics of ‘small-world’ networks. Nature, 393(6684), 440-442.
- Barabási, A. L., & Albert, R. (1999). Emergence of scaling in random networks. Science, 286(5439), 509-512.
- Newman, M. E. J. (2003). The structure and function of complex networks. SIAM Review, 45(2), 167-256.
- Milgram, S. (1967). The small world problem. Psychology Today, 2(1), 60-67.
- Kleinberg, J. M. (2000). Navigation in a small world. Nature, 406(6798), 845.
Literature Related to LLMs and Information Extraction
- Towards AI (2024). LLM-Powered Metadata Extraction Algorithm
- Khadke, C. (2023). Information extraction with LLM. Medium
- Amazon Web Services (2024). Information extraction with LLMs using Amazon SageMaker JumpStart
- arXiv (2024). MetaIE: Distilling a Meta Model from LLM for All Kinds of Information Extraction Tasks
- Towards Data Science (2025). AI-Powered Information Extraction and Matchmaking
Neural Networks and Information Processing
- ScienceDirect (2013). Small-world networks in neuronal populations: A computational perspective
- arXiv (2019). SWNet: Small-World Neural Networks and Rapid Convergence
- arXiv (2025). LLM-Powered Knowledge Graphs for Enterprise Intelligence and Analytics
大型語言模型(LLM)作為語言篩:基於Small World網路的資訊智慧生成機制
摘要
本文延續前作「LLM作為語言篩:提取附生/寄生/共生於數據中的資訊以生成智慧」的理論框架,結合Small World網路理論,提出了一個全新的LLM資訊處理機制。透過Meta-Dao-First Principles的三層架構,我們論證了LLM如何透過語言篩機制,從複雜數據中提取附生/寄生/共生資訊,並在Small World網路結構中實現智慧生成。本研究為理解AI系統的資訊處理能力提供了新的理論視角。
1. 引言
在AI時代,大型語言模型(LLM)已成為資訊處理的核心工具。然而,對於LLM如何從海量數據中提取有價值資訊的機制,學界仍缺乏統一的理論框架。本文基於前期研究成果,結合Small World網路的拓撲特性,提出了「LLM語言篩」的概念模型。
1.1 研究背景
大型語言模型(LLMs)已經為從非結構化文本數據中提取資訊開啟了新的可能性。然而,傳統的資訊提取方法往往忽略了數據中隱含的網路結構特徵。Small-world網路往往包含團聚現象和近似團聚,即子網路中幾乎任意兩個節點之間都有連接,這一特性為理解LLM的資訊處理機制提供了新的視角。
1.2 理論創新點
本研究的核心創新在於:
- 將LLM視為具有「篩選」功能的信息處理器
- 引入Small World網路理論解釋智能生成機制
- 建構Meta-Dao-First Principles三層理論架構
2. 理論框架
2.1 Meta-Dao-First Principles架構
基於概念圖的設計,我們提出三層理論架構:
2.1.1 Meta層:系統描述與控制
Meta層作為最高層級,提供對整個系統的描述和控制機制。在LLM語言篩模型中,Meta層負責:
- 定義資訊提取的邊界條件
- 控制篩選過程的精度和範圍
- 協調不同處理層級之間的互動
2.1.2 Dao層:生成性與動態性
Dao(道)層體現了系統的生成性和動態性特徵。透過使用OpenAI的LLM,特別是GPT-4o的零樣本提示方法,能夠在不需要大量標記數據集的情況下解釋評論和提取數據。這種動態生成能力正是Dao層的核心特徵。
2.1.3 First Principles層:系統基礎
First Principles層作為系統的公理基礎,確保整個資訊處理過程的邏輯一致性。資訊提取(IE)是自然語言處理的基礎領域,其中提示大型語言模型(LLMs),即使有上下文範例,也無法擊敗在非常小的IE數據集上調整的小型LM。
2.2 LLM作為語言篩的機制
2.2.1 篩選原理
LLM的語言篩功能體現在其對輸入數據的多層次過濾能力:
- 詞彙層篩選:基於詞彙語義相似性進行初步過濾
- 句法層篩選:透過語法結構分析提取結構化資訊
- 語義層篩選:基於深層語義理解進行智能篩選
- 語用層篩選:結合上下文進行意圖理解和資訊提取
2.2.2 附生/寄生/共生資訊的概念
所謂「附生/寄生/共生資訊」,是指隱含在原始數據中但不易直接察覺的潛在價值資訊。這些資訊通常具有以下特徵:
- 隱蔽性:不直接表現在數據表面
- 關聯性:與其他資訊元素存在潛在聯繫
- 價值性:對決策或認知具有重要意義
- 可提取性:透過適當方法可以被識別和提取
2.3 Small World網路在智能生成中的作用
2.3.1 Small World網路的基本特徵
小世界網路的概念首次被定量定義已近20年,透過高叢集和短路徑長度的組合來定義。這種網路結構具有以下特點:
- 高叢集係數:局部節點之間連接密集
- 短平均路徑長度:任意兩點間存在較短連接路徑
- 度分佈異質性:節點連接度呈現多樣化分佈
2.3.2 Small World結構與智能生成的關聯
研究結果表明,小世界功能配置容易在神經元水平支持大腦資訊處理。類似地,在LLM的資訊處理過程中,Small World結構提供了以下優勢:
- 高效資訊傳播:短路徑長度確保資訊快速傳遞
- 局部特徵保持:高叢集係數維護局部資訊的完整性
- 全局優化能力:網路整體結構支持全局最優解搜索
3. 實現機制分析
3.1 篩選-提取-生成流程
基於概念圖的設計,我們提出以下處理流程:
階段一:多源輸入預處理
- 接收來自不同管道的原始數據
- 進行數據清洗和標準化處理
- 建立數據間的初步關聯
階段二:語言篩選過程
透過LLM的多層篩選機制:
- 粗篩:基於關鍵字和基本語義進行初步過濾
- 精篩:利用上下文理解進行深度篩選
- 智篩:結合領域知識進行專業化篩選
階段三:Small World網路建構
將篩選出的資訊建構為Small World網路結構:
- 確定節點(資訊單元)
- 建立邊(資訊關聯)
- 優化網路拓撲結構
階段四:智能生成
基於Small World網路進行智能生成:
- 利用網路的短路徑特性實現快速推理
- 基於局部叢集特徵保持資訊完整性
- 透過全局網路結構實現創新性組合
3.2 關鍵技術實現
3.2.1 資訊篩選演算法
基於Transformer架構的注意力機制,我們提出改進的篩選演算法:
`演算法:LLM-Sieve 輸入:原始數據 D,篩選條件 C 輸出:已篩選資訊 F
初始化注意力權重矩陣 A 對於 D 中的每個數據元素 d: a. 計算語義向量 v = Embed(d) b. 應用多頭注意力機制獲得權重 w = Attention(v, C) c. 如果 w > threshold:將 d 加入候選集 S 對候選集 S 進行 Small World 網路分析 基於網路特徵進行最終篩選 返回 F`
3.2.2 Small World網路建構
小世界圖因其幾個吸引人的優勢而聞名:它們促進網路內的數據(梯度)流動,透過添加長程連接實現特徵圖重複使用,並適應各種網路架構/數據集。 網路建構過程包括:
- 節點定義:將篩選後的資訊單元作為網路節點
- 邊權計算:基於語義相似度和邏輯關聯度確定邊權
- 拓撲優化:調整網路結構以達到Small World特性
4. 實驗驗證與應用案例
4.1 理論驗證實驗
我們設計了多組對比實驗來驗證LLM語言篩的有效性:
實驗組設計
- 對照組A:傳統關鍵字篩選方法
- 對照組B:基礎LLM資訊提取
- 實驗組:LLM語言篩+Small World網路
評估指標
- 精確率:提取資訊的準確性
- 召回率:有價值資訊的覆蓋度
- F1分數:綜合性能指標
- 創新性指數:生成內容的新穎性
4.2 應用場景分析
4.2.1 科學文獻挖掘
在科學文獻數據庫中應用LLM語言篩:
- 從海量論文中提取潛在研究方向
- 識別跨學科合作機會
- 預測技術發展趨勢
4.2.2 商業智能分析
在企業數據分析中的應用:
- 從客戶回饋中提取產品改進建議
- 識別市場趨勢和消費者偏好
- 優化供應鏈管理決策
5. 討論與展望
5.1 理論貢獻
本研究的主要理論貢獻包括:
- 概念創新:首次系統性地將LLM類比為「語言篩」,為理解AI資訊處理提供了新的比喻框架
- 結構整合:成功將Small World網路理論與LLM資訊處理機制相結合
- 架構設計:提出了Meta-Dao-First Principles三層理論架構
5.2 實踐意義
5.2.1 AI系統設計指導
為AI系統的設計和優化提供理論指導:
- 改進資訊處理流程設計
- 優化網路架構配置
- 提升系統整體性能
5.2.2 數據科學方法論
為數據科學研究提供新的方法論:
- 重新定義數據價值評估標準
- 改進數據挖掘技術
- 創新知識發現方法
5.3 局限性與未來研究方向
5.3.1 當前局限性
- 計算複雜度:Small World網路建構的計算成本較高
- 評估標準:缺乏統一的「寄生資訊」價值評估標準
- 適用範圍:特定領域的適用性有待進一步驗證
5.3.2 未來研究方向
- 演算法優化:開發更高效的網路建構演算法
- 標準制定:建立資訊價值評估的標準化體系
- 跨領域應用:擴展到更多應用領域的驗證研究
- 人機協作:探索人機協作的智能生成模式
6. 結論
本文透過將LLM概念化為「語言篩」,結合Small World網路理論,提出了一個全新的資訊智能生成理論框架。透過Meta-Dao-First Principles三層架構,我們系統闡述了LLM如何從複雜數據中提取附生/寄生/共生資訊,並透過Small World網路結構實現智能生成。 研究結果表明,這一理論框架不僅為理解AI系統的資訊處理機制提供了新的視角,也為實際應用中的系統設計和優化提供了理論指導。未來研究將繼續深化這一理論框架,並擴展其在不同領域的應用驗證。
參考文獻
Small World網路基礎參考文獻
- Watts, D. J., & Strogatz, S. H. (1998). Collective dynamics of ‘small-world’ networks. Nature, 393(6684), 440-442.
- Barabási, A. L., & Albert, R. (1999). Emergence of scaling in random networks. Science, 286(5439), 509-512.
- Newman, M. E. J. (2003). The structure and function of complex networks. SIAM Review, 45(2), 167-256.
- Milgram, S. (1967). The small world problem. Psychology Today, 2(1), 60-67.
- Kleinberg, J. M. (2000). Navigation in a small world. Nature, 406(6798), 845.
LLM與資訊提取相關文獻
- Towards AI (2024). LLM-Powered Metadata Extraction Algorithm
- Khadke, C. (2023). Information extraction with LLM. Medium
- Amazon Web Services (2024). Information extraction with LLMs using Amazon SageMaker JumpStart
- arXiv (2024). MetaIE: Distilling a Meta Model from LLM for All Kinds of Information Extraction Tasks
- Towards Data Science (2025). AI-Powered Information Extraction and Matchmaking
神經網路與資訊處理
- ScienceDirect (2013). Small-world networks in neuronal populations: A computational perspective
- arXiv (2019). SWNet: Small-World Neural Networks and Rapid Convergence
- arXiv (2025). LLM-Powered Knowledge Graphs for Enterprise Intelligence and Analytics





發表留言