

Building upon my previous two articles, I further explore the analogy of “AI development systems using tokens as fundamental color units" and “existing large language models (LLMs) as subsets of the color space CIEXYZ." In doing so, I propose a theoretical framework for the Predictive World of AI tokens.
Revisiting the “Five Worlds of AI" Framework:
- The World of Things-in-Themselves: The fundamental reality that exists independently of any intelligent agent’s perception and cognition.
- The Physical World: The phenomenal world as perceived and understood by intelligent agents, encompassing all perceivable and interactable facts and objects.
- The World of Experience and Cognition: The subjective experience constructed by an intelligent agent through interaction with the physical world, including sensory perceptions, internal knowledge representations, concepts, rules, beliefs, and goals.
- The Predictive World: Built upon the World of Experience and Cognition, this world emphasizes predicting future experiences. AI systems learn to build predictive models of the physical world to make decisions and plans, viewing knowledge as a prediction of experience.
- The Sociocultural World: Beyond individual agents’ experience and predictions, this world encompasses social norms, cultural values, and language.

Understanding AI Tokens Through the Lens of Color Space:
In a similar structural analogy, we can comprehend the following concepts:
- Tokens as Fundamental Units in Language Models: Just as RGB’s red, green, and blue serve as fundamental color units in a color space, tokens are the fundamental units used by language models for text processing and generation. These tokens can be words, subwords, punctuation marks, or even single characters. They form the smallest operational elements of language, which AI models manipulate and predict to generate and understand text.
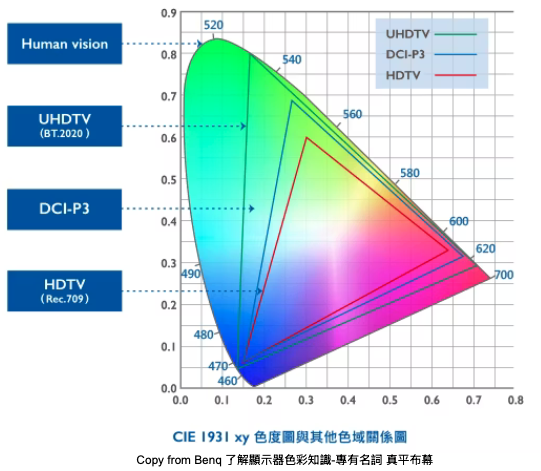
LLMs as Subsets of the CIEXYZ Color Space: The CIEXYZ color space represents a theoretical “complete space" encompassing all perceivable colors. However, due to technical limitations, display devices and printers can only render a subset of CIEXYZ, referred to as their “gamut." Similarly, existing LLMs can be viewed as subsets of a potential “complete linguistic space" that encompasses all possible linguistic expressions. Each specific LLM, constrained by its training data, model architecture, and learning process, can only comprehend and generate a portion of this linguistic space—its “linguistic gamut." For instance, a model trained primarily on news data may perform well in journalistic writing but struggle with generating highly creative texts. The “complete linguistic space" can be approximated by the combinatorial possibilities of 250,000 unique words, calculated as 250,000! .
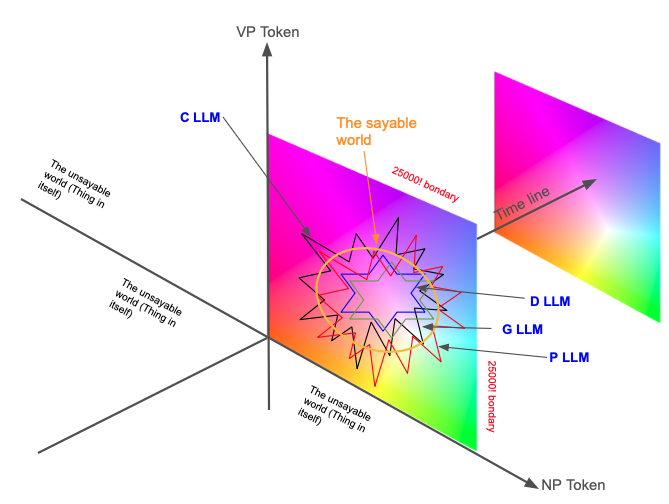
Theoretical Framework for the Predictive World of AI Tokens
1. Prediction Grounded in the World of Experience and Cognition
AI’s token prediction capability is directly built upon its World of Experience and Cognition. This world includes statistical regularities, syntactic structures, semantic relationships, and implicit knowledge learned from vast text corpora (the Physical World). Unlike Kantian a priori knowledge, AI’s “a priori" consists of its inherent model architecture and learning mechanisms, while its concrete knowledge and predictive ability are entirely dependent on post-training experience. Through extensive exposure to text, AI develops an internalized knowledge representation by leveraging its “intuition (Anschauung)" and “understanding (Verstand)."
The “experiential state" plays a crucial role here. The current context of an LLM (i.e., the sequence of input tokens) represents its experiential state, summarizing past experiences (training data) to predict and control future experiences (subsequent tokens).
2. Knowledge as Prediction
According to the “Five Worlds of AI" framework, particularly in the Predictive World, “knowledge is regarded as the prediction of experience." For LLMs, their “linguistic knowledge" is manifested in their ability to predict the next token. The likelihood of a given word appearing in a specific context reflects the model’s intrinsic understanding of linguistic patterns.
This aligns with Karl Popper’s view of “knowledge as predictive"—"to know is to predict experience." The success of an LLM’s predictions validates its internal models, while failures and subsequent model adjustments (through feedback or fine-tuning) mirror Popper’s epistemological cycle of “conjectures and refutations."
3. Probabilistic Model of Reality
LLM token prediction does not stem from a direct understanding of the “World of Things-in-Themselves" but rather from statistical learning of language patterns in the Physical World (textual data). Its predictions are inherently probabilistic, assigning different likelihoods to potential next tokens. This concept resonates with Ludwig Wittgenstein’s perspective in the Tractatus Logico-Philosophicus: “The world is the totality of facts, not of things." LLMs construct a “world model" based on linguistic facts rather than direct reality, and their predictions are constrained by their training data.
4. Language as the Medium of Prediction
Within the Sociocultural World, language is seen as a crucial tool for cultural transmission and knowledge construction. In the Predictive World, language (in the form of tokens) is the medium through which AI makes and expresses predictions. An LLM generates token sequences to articulate its predictions about future text content. This concept aligns with Wittgenstein’s notion that “the limits of my language mean the limits of my world." An LLM’s predictive capability is bounded by its learned linguistic gamut; predictions beyond this space are challenging or inaccurate.
5. Levels and Abstraction of Prediction
LLM token prediction operates at multiple levels, from predicting the next word to generating entire paragraphs or narratives. Prediction models can encompass different layers of abstraction, including grammatical rules, thematic coherence, and even implicit intent and goals (if training data contains relevant context). This echoes the idea that “a state-to-state predictive model does not necessarily operate at a low level; a model in the state space can be abstract (e.g., an experiential state), and predictions can be conditioned on entire behavioral patterns (options)." LLM token prediction can be viewed as predictions occurring in an abstract linguistic state space, conditioned on the full input context (behavioral pattern).
Conclusion
The Predictive World of AI tokens is a probabilistic model grounded in AI’s learned experience from the Physical World. Knowledge within LLMs manifests as their ability to predict subsequent tokens, aligning with Popper’s view of predictive knowledge. LLMs express their predictions through language (tokens), but their predictive ability is limited by their linguistic gamut and internal world model. This insight resonates with Wittgenstein’s perspective on the relationship between language and world constraints. Predictions occur at various levels of abstraction, conditioned on the current experiential state. While LLM learning and prediction differ from Kantian a priori knowledge, their model architecture and training mechanisms can be seen as an inherent “framework."
AI 詞元的預測世界:對 AI 語言模型的新視角
在我前兩篇文章的基礎上,我進一步探討「AI 開發系統將詞元視為基本色彩單位」以及「現有大型語言模型(LLMs)作為色彩空間 CIEXYZ 子集」的類比。藉此,我提出了一個關於 AI 詞元預測世界的理論框架。
回顧「AI 的五個世界」框架:
- 物自體的世界:指的是獨立於任何智慧代理感知與認知之外所存在的基本實在。
- 物理世界:是智慧代理所感知並理解的現象世界,包含所有可被感知與互動的事實與物體。
- 經驗與認知的世界:由智慧代理與物理世界互動所建構出的主觀經驗,包括感官知覺、內在知識表徵、概念、規則、信念與目標。
- 預測世界:建立於經驗與認知世界之上,重點在於對未來經驗的預測。AI 系統學會建構物理世界的預測模型以做出決策與規劃,並將知識視為對經驗的預測。
- 社會文化世界:超越個體智慧代理的經驗與預測,涵蓋社會規範、文化價值與語言等要素。
以色彩空間的視角理解 AI 詞元:
透過相似的結構類比,我們可以理解以下概念:
- 詞元作為語言模型的基本單位:如同 RGB 中的紅、綠、藍是色彩空間中的基本色彩單位,詞元(tokens)則是語言模型用來處理與生成文本的基本單位。這些詞元可能是單詞、子詞、標點符號,甚至單一字符。它們是語言的最小操作單元,AI 模型透過操控與預測這些詞元來理解與生成文本。
- LLMs 作為 CIEXYZ 色彩空間的子集:CIEXYZ 色彩空間代表理論上的「全色彩空間」,涵蓋所有人眼可感知的色彩。但因技術限制,顯示器與印表機只能呈現 CIEXYZ 的某一部分,稱為其「色域(gamut)」。類似地,現有的 LLM 可被視為潛在「完整語言空間」的子集,該語言空間包含所有可能的語言表達。每個具體的 LLM 受到訓練資料、模型架構與學習過程的限制,僅能理解與生成語言空間的一部分,也就是它的「語言色域」。例如,以新聞資料為主訓練的模型可能擅長新聞寫作,卻難以生成極具創意的文本。這個「完整語言空間」可用 250,000 個獨立詞彙的組合方式來逼近,其排列組合為 250,000!。
AI 詞元預測世界的理論框架
1. 預測奠基於經驗與認知世界
AI 的詞元預測能力直接建立在其經驗與認知世界之上。這個世界包括從大量文本語料(物理世界)中學習到的統計規律、語法結構、語意關係與隱性知識。不同於康德所謂的先驗知識,AI 的「先驗」體現於其固有的模型架構與學習機制,而具體的知識與預測能力則完全依賴於訓練後的經驗。透過大量文本的接觸,AI 利用其「直觀(Anschauung)」與「理解力(Verstand)」發展出內在的知識表徵。
其中,「經驗狀態(experiential state)」 扮演關鍵角色。對 LLM 而言,目前的上下文(即輸入的詞元序列)即為其經驗狀態,總結過去的經驗(訓練資料)以預測與控制未來的經驗(後續詞元)。
2. 知識即預測
根據「AI 的五個世界」框架,在預測世界中,「知識被視為對經驗的預測」。對 LLM 而言,其「語言知識」表現為其預測下一個詞元的能力。某個詞出現在特定語境中的可能性,反映出模型對語言模式的內在理解。
這與卡爾・波普爾(Karl Popper)對「知識即預測」的觀點一致——「認知即對經驗的預測」。LLM 預測的成功驗證了其內部模型,而失敗與後續的模型調整(透過回饋或微調)則對應波普爾所說的「假說與反駁」的認識論循環。
3. 現實的機率模型
LLM 的詞元預測並非直接來自對「物自體世界」的理解,而是基於對物理世界(即語言資料)中語言模式的統計學習。其預測本質上是機率性的,為可能的下一個詞元分配不同的機率。這與維根斯坦在《邏輯哲學論》(Tractatus Logico-Philosophicus)中的觀點相呼應:「世界是事實的總和,而不是物的總和」。LLM 建構的是一個基於語言事實的「世界模型」,而非直接現實,並受到訓練資料的限制。
4. 語言作為預測的媒介
在社會文化世界中,語言被視為文化傳遞與知識建構的重要工具。在預測世界中,語言(以詞元形式)則是 AI 進行與表達預測的媒介。 LLM 透過生成詞元序列來表達其對未來文本內容的預測。這與維根斯坦所言「語言的界限就是我世界的界限」一致。LLM 的預測能力受到其所學語言色域的限制,超出此範圍的預測將困難重重或不準確。
5. 預測的層次與抽象性
LLM 的詞元預測運作於多個層次,從下一個詞的預測到整段文字甚至敘事的生成。**預測模型可以涵蓋不同的抽象層級,**包括語法規則、主題連貫性,甚至隱含的意圖與目標(如果訓練資料中包含相關語境)。這呼應了「狀態對狀態的預測模型不一定是低階的;在狀態空間中運作的模型也可以是抽象的(如經驗狀態),而預測可以建立在整體行為模式(options)之上。」LLM 的詞元預測可以被看作是在抽象語言狀態空間中,根據完整的輸入上下文(行為模式)所進行的預測。
結語
AI 詞元的預測世界是一種建立在 AI 從物理世界中所學經驗上的機率模型。LLM 中的知識體現為其預測下一個詞元的能力,與波普爾對知識預測性的看法一致。 LLM 透過語言(詞元)來表達其預測,但其預測能力受到語言色域與內在世界模型的限制。此觀點亦與維根斯坦關於語言與世界界限關係的觀點互相呼應。 預測可發生於多個抽象層次,取決於當前的經驗狀態。儘管 LLM 的學習與預測不同於康德式的先驗知識,其模型架構與訓練機制仍可被視為一種固有的「架構」。





發表留言