

AI hallucinations are often seen as one of the biggest problems in large language models (LLMs). But could some unintentional hallucinations actually have value? This article explores that possibility by drawing on the concept of deviance from The Deviant’s Advantage (Ryan Mathews & Watts Wacker).
In The Deviant’s Advantage, the authors argue that deviance—defined as actions or ideas that diverge from the norm—can be a source of innovation and growth. They describe deviance as the work of “cultural laggards” who are able to recognize opportunities created by change and transform marginal ideas into mainstream breakthroughs.
If we consider AI hallucinations as a form of deviance, we can begin to see their potential value. AI hallucination refers to outputs that are factually incorrect, baseless, or difficult to explain. But if we treat these hallucinations as the model exploring beyond the current boundaries of human knowledge, they become manifestations of the AI’s deviation from normal cognition. “Everything different is, by nature, a deviation," and positive deviance can become a transformative force.
Though often regarded as errors, hallucinations may touch on the edges of a model’s internal representations, revealing limitations in understanding—and thus offering clues for expanding human or artificial intelligence.
Sometimes, what seems like an error or nonsense might actually contain an unexpected understanding of hidden patterns or associations in the data. If properly uncovered and directed, these can lead to new knowledge or novel problem-solving approaches. AI hallucinations may also transcend the limitations of human language. In creative domains like art, they might produce unique styles or combinations that humans have never imagined—“mistakes” that inspire artists and spark new forms of artistic expression. In scientific discovery, unexpected results (a type of hallucination) from analyzing large datasets might point to overlooked phenomena or emerging patterns.
Still, AI hallucinations come with risk. That’s why we need a structured framework to understand and harness hallucinations—extracting value while managing potential harm:
1. Value at the Edge
- View hallucinations as explorations at the boundary of a model’s knowledge.
- Analyze hallucinated content to identify knowledge gaps or representational biases.
- Look for hallucinations that appear irrational but might contain novel ideas or associations.
- Explore how we might deliberately induce “creative hallucinations” in controlled settings—through prompt design or parameter tuning—to probe the model’s cognitive edge.
2. How to Compare Hallucination Data
- Classify hallucinations by type for better comparison.
- Compare hallucinations across different models, parameter settings, or training datasets.
- Study the contextual patterns that lead to certain hallucination types.
- Use statistical analysis to study hallucination trends and distribution—for instance, which domains are most susceptible or which parameters lead to higher rates.
- Examine specific cases to better understand the model’s knowledge map.
- Explore interrelations among hallucinations—e.g., whether certain types co-occur frequently.
- Apply NLP techniques to analyze hallucination content and discover underlying themes or patterns.
3. How to Redefine Problems and Judgments
- In exploratory tasks, relax strict correctness constraints and allow a degree of deviance to assess its creative or innovative value.
- Based on an understanding of hallucinations, redefine the human role in human-AI collaboration systems—shifting from strict supervision to guided exploration.
4. Adjust Parameters
- Tune generation parameters to modulate hallucination frequency and behavior.
5. Test
- After adjustments, conduct new rounds of systematic testing to gather updated hallucination data.
6. How to Collect Hallucination Data
- Automatically log model outputs and annotate segments that contradict known facts or commonsense as hallucinations.
- Design human evaluation mechanisms, where domain experts judge and categorize potential hallucinations.
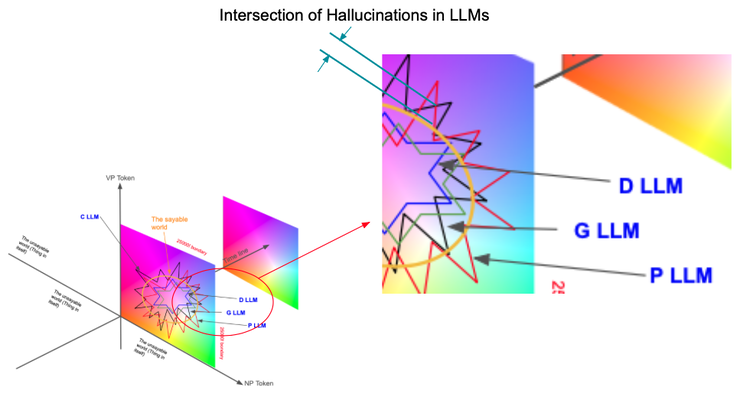
7. Intersection of Hallucinations in LLMs
- Systematically observe hallucinations produced by different LLMs given the same or similar input.
- Focus on hallucinations that repeatedly appear in specific domains or tasks—they might hint at overlooked phenomena or hidden structures.
- Record the context in which hallucinations occur, including prompts, model settings, and related output, to better understand their origins.
8. Introduce Valuable Cognitive Insights
By using this framework, we can transform AI hallucinations from mere “errors" into valuable insights for understanding models and discovering hidden innovation. With an open and exploratory mindset, we treat these “deviant” behaviors not as problems to eliminate but as opportunities to study—and we build scientific methods to analyze and leverage these unusual outputs.
AI 幻覺的價值:來自異端的優勢(邊緣創意的生成)
AI 幻覺(AI hallucinations)常被視為大型語言模型(LLMs)的一大問題。然而,有些非刻意產生的幻覺是否可能反而具有價值?本文透過《異端的優勢》(The Deviant’s Advantage,作者 Ryan Mathews 與 Watts Wacker)一書中的「異端」(deviance)概念,探討這樣的可能性。
在《異端的優勢》中,作者主張「異端」——意指偏離常規的行為或想法——可以成為創新與成長的泉源。他們將異類描述為那些「文化落後者」的行動,這些人能察覺由變化所帶來的機會,並將邊緣想法轉化為主流突破。
若我們將 AI 幻覺視為一種異端行為,便能開始看見它的潛在價值。AI 幻覺是指那些事實錯誤、毫無根據,或難以解釋的輸出內容。但若我們將其視為模型探索人類知識邊界的一種方式,幻覺便成為 AI 偏離常規認知的展現。「所有不同的事物,本質上都是一種偏離」,而正向異端行為可以成為轉變的力量。
儘管幻覺常被視為錯誤,它們可能觸及模型內部表示的邊界,揭露理解上的限制——因此也可能提供擴展人類或人工智慧知能的線索。
有時,看似錯誤或無稽之談的內容,其實可能包含對隱藏模式或資料間關聯的意外理解。若能妥善挖掘並引導,這些幻覺有機會引領我們發現新知識或嶄新的問題解決方式。AI 幻覺甚至有可能超越人類語言的限制。在藝術等創造性領域中,AI 可能產出人類未曾想像的獨特風格或組合——這些所謂的「錯誤」,或許正能激發藝術家的靈感,並引發全新的藝術表現形式。在科學發現方面,來自龐大數據分析的意外結果(一種幻覺)也可能揭示被忽略的現象或新興模式。
當然,AI 幻覺也伴隨著風險。因此,我們需要一個結構化的框架來理解與利用幻覺——在管理潛在傷害的同時,萃取其價值:
1. 邊界的價值
- 將幻覺視為模型知識邊界的探索。
- 分析幻覺內容,找出知識缺口或表示偏差。
- 尋找那些表面看似不合邏輯,但可能包含新想法或聯結的幻覺。
- 探索在可控環境下(如提示詞設計或參數調整)刻意誘發「創意型幻覺」,藉此探索模型的認知邊界。
2. 比較幻覺資料的方法
- 將幻覺按類型分類,以利比較。
- 比較不同模型、參數設定或訓練資料下產生的幻覺。
- 研究導致某些幻覺類型的上下文模式。
- 使用統計分析觀察幻覺的趨勢與分布,例如:哪些領域最易產生幻覺、哪些參數導致幻覺率上升。
- 透過具體案例深入了解模型的知識地圖。
- 探索不同幻覺間的關聯性——例如某些類型是否常同時出現。
- 應用自然語言處理技術,分析幻覺內容,找出潛在主題或模式。
3. 重新定義問題與評判標準
- 在探索性任務中,放寬正確性的嚴格限制,允許一定程度的偏離,以評估其創造性或創新價值。
- 根據對幻覺的理解,重新定義人類在人機協作系統中的角色——從嚴格監控者轉變為引導探索的導師。
4. 調整參數
- 調整模型生成參數,以控制幻覺的頻率與行為表現。
5. 測試
- 完成參數調整後,進行新一輪系統性測試,以收集更新後的幻覺資料。
6. 收集幻覺資料的方法
- 自動記錄模型輸出,並標註那些違反已知事實或常識的部分為幻覺。
- 設計人類評估機制,由領域專家判斷並分類潛在幻覺。
7. LLM 幻覺的交集分析
- 系統性觀察不同 LLM 在相同或相似輸入下產生的幻覺。
- 聚焦於那些在特定領域或任務中反覆出現的幻覺——它們可能暗示被忽視的現象或隱藏的結構。
- 記錄幻覺出現的上下文,包括提示詞、模型設定與相關輸出,以更好理解幻覺的成因。
8. 引入有價值的認知洞察
透過這套框架,我們可以將 AI 幻覺從單純的「錯誤」轉化為理解模型與發掘隱藏創新的有價值洞察。若我們抱持開放與探索的心態,將這些「異端行為」視為研究機會,而非必須根除的問題,就能建立一套科學方法,來分析並利用這些不尋常的輸出。





發表留言