

The Boundaries of the World Shaped by Large Language Models
Introduction
In 1989, Richard Saul Wurman published his classic book Information Anxiety, describing the widening gap between “what we truly understand" and “what we think we should understand." At the time, he warned of the overwhelming effects of the information explosion. Fast forward to today, and artificial intelligence (AI) has drastically changed the nature of this problem. While information overload remains unavoidable, it has become less of a concern. Instead, a new anxiety has emerged—fear of being replaced by AI.
With vast amounts of expert-level knowledge readily available at our fingertips, the accessibility of information has reshaped our perception of expertise. We no longer worry about drowning in information but rather about whether AI will render human knowledge redundant. This shift in anxiety has even given rise to apocalyptic narratives about AI surpassing human intelligence.
Humans have long absorbed information over time, often struggling to digest its sheer volume. AI, however, does not suffer from cognitive overload; its limitations stem from computational constraints, memory scalability, and processing speed. The real challenge for AI is the insufficiency of raw data, as its advancement and evolution rely on extensive training datasets. The closer its generated data aligns with human needs, the more seamlessly it integrates into our world.
A Framework for Understanding the World
To navigate this evolving landscape, I believe in constructing a cognitive framework for understanding the world—a paradigm that helps organize information into a coherent structure. This concept aligns with Thomas Kuhn’s The Structure of Scientific Revolutions, where he introduces the idea of paradigm shifts as nonlinear and disruptive changes in scientific thought. Kuhn defines a paradigm as the collective worldview accepted by a scientific community. Similarly, my personal worldview is structured through a cognitive framework that helps me process information systematically rather than chaotically.
While I do not subscribe to strict determinism, I firmly believe that having a structured framework increases our ability to comprehend and manage the world. However, such a framework should not be mistaken for a rigid set of rules or a formalized theory—it is a flexible, evolving perspective that shapes how I interpret knowledge.
Popper, Wittgenstein, and the Limits of Knowledge
Karl Popper’s falsification theory remains a subject of debate, but I find his Three Worlds Theory particularly intriguing. In Objective Knowledge: An Evolutionary Approach, Popper categorizes reality into three distinct worlds:
- World 1: The physical world, consisting of biological entities, objects, and events.
- World 2: The subjective world of human consciousness and perception.
- World 3: The world of objective knowledge, including human culture, theories, and intellectual artifacts.
Ludwig Wittgenstein, in his Tractatus Logico-Philosophicus, introduces another perspective, dividing the world into two realms: the sayable (what can be expressed in language) and the unsayable (what lies beyond linguistic representation)—the realm of mysticism. His famous assertion, “The limits of my language mean the limits of my world," has profoundly influenced my thinking.
By juxtaposing Popper’s and Wittgenstein’s frameworks, I developed a subjective perspective: associating Worlds 2 and 3 with Wittgenstein’s linguistic world, while placing Wittgenstein’s unsayable world (Kant’s “Thing in itself") before World 1. Cognitive scientist Donald Hoffman’s Interface Theory of Perception (ITP) explains that, based on findings from both quantum physics and evolutionary biology, our senses guide us toward perceptions that facilitate useful actions. Through natural selection, our sensory perceptions are continuously refined. However, there is often a trade-off between fitness and accuracy (truth) Due to these constraints, our ability to fully comprehend the cognitive world is inherently limited and bounded.
The Boundaries of LLMs: A New World in the Cognitive Paradigm
On November 30, 2022, OpenAI released the first version of GPT-3.5, a model trained on massive textual datasets, capable of recognizing and generating human-like language. At its core, LLMs operate on probabilistic prediction—computing the most likely next word in a sequence using high-dimensional vector representations of language. This fundamentally ties LLMs to the spatiotemporal nature of language, as they attempt to align their outputs with human cognitive models.
Copy from YouTube video of 3blue 1 Brown
Some speculate that AI will eventually become an autonomous agent, shaping society, history, and culture beyond human control. While I remain skeptical of such claims, I acknowledge the inherent flaw in LLMs: hallucinations—the tendency to generate information that appears plausible but is factually incorrect. Geoffrey Hinton, the “Godfather of AI," has warned about AI’s ability to generate misleading text and images, potentially flooding the internet with falsehoods. I think that the threat AI poses extends beyond mere survival—it also challenges cultural stability and intellectual integrity.
The Limits of Language and the Expansion of AI
The underlying structure of LLM models primarily consists of English words and numerical code. The English language is estimated to have around 250,000 words. If we consider permutations, with 250,000 distinct words, the total number of possible arrangements is 250,000 factorial, written as 250,000!. Factorial notation represents the product of all positive integers up to that number:
250,000! = 250,000 × 249,999 × 249,998 × … × 2 × 1.
However, 250,000! is an extraordinarily large number, far beyond the computational capacity of standard calculators or even most computers. Even with high-precision computing tools, calculating such a massive factorial value is extremely challenging. Therefore, logarithms or approximations like Stirling’s formula are commonly used to estimate such large numbers.
Stirling’s approximation states that: n! ≈ √(2πn) × (n/e)^n
Applying this to n = 250,000, we get:
250,000! ≈ √(2π × 250,000) × (250,000 / e)^250,000
This approximation still results in an unimaginably large number. And that leads me to my main hypothesis for today: the boundary of the AI world in LLMs is 250,000!
The boundaries of the AI world in LLMs, combined with my earlier discussion, lead me to incorporate Wittgenstein’s concept of the “unspeakable world" (Thing in itself) into my own world cognition framework paradigm.I position the AI world of LLMs between Popper’s World 2 (the world of mental states) and World 3 (the world of objective knowledge), forming a five-layered world cognition structure. This framework represents my complete internal epistemological system.
- World 1: The unsayable world (Thing in itself).
- World 2: The physical world of biological entities, objects, and events.
- World 3: The human linguistic world, shaped by perception and cognition.
- World 4: The LLM-generated AI world, governed by computational probability.
- World 5: The world of objective knowledge and intellectual artifacts.
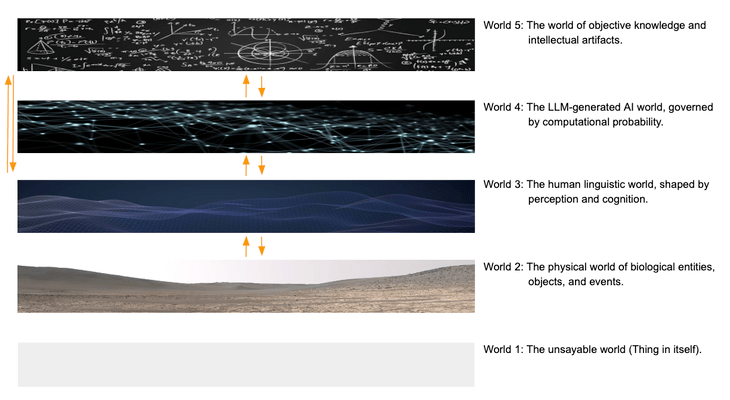
five-layered world cognition structure
AI, Cultural Disruption, and the Future of Knowledge
The true danger of AI is not just in its potential to deceive but in its ability to erode originality. As the demand for LLM training data grows, we face a looming crisis: the depletion of original content. Texts and images generated by AI are gradually replacing human-created content, reducing the incentive for authentic artistic and intellectual expression. Even in the physical world, 3D printing enables infinite replication, diminishing the uniqueness of handcrafted objects.
While LLMs may become more refined and cost-effective, their progress remains internally competitive rather than outwardly expansive for capabilities. As AI-generated content becomes the dominant form of knowledge production, it could hinder humanity’s drive for original thought. This, in turn, poses a direct threat to World 5—the world of objective knowledge, stalling its expansion and blurring the boundaries between truth and fabrication.
The antidote to AI-induced “replacement anxiety" lies in fostering human originality. By preserving and encouraging creative endeavors, we safeguard the expansion of human knowledge and protect the cultural fabric that defines our collective intelligence.
人工智慧大型語言模型(LLM)的邊界(一個想法)
由大型語言模型塑造的世界邊界
引言
1989年,Richard Wurman出版了他的經典著作《資訊焦慮》,描述了「我們真正理解的」和「我們認為我們應該理解的」之間的差距越來越大。 當時,他警告說資訊爆炸的壓倒性影響。 快進到今天,人工智慧(AI)極大地改變了這個問題的性質。 雖然資訊過載仍然是不可避免的,但它變得不那麼令人擔憂了。 相反,出現了一種新的焦慮——害怕被人工智慧取代。
大量的專家級知識觸手可及,資訊的可訪問性重塑了我們對專業知識的看法。 我們不再擔心淹沒在資訊中,而是擔心人工智慧是否會使人類知識變得多餘。 這種焦慮的轉變甚至引發了關於人工智慧超越人類智力的世界末日敘事。
隨著時間的推移,人類長期吸收資訊,經常努力消化其大量資訊。 然而,人工智慧並沒有受到認知過載的影響;它的侷限性源於計算約束、記憶體可擴充套件性和處理速度。 人工智慧的真正挑戰是原始資料的不足,因為它的進步和演變依賴於廣泛的訓練資料集。 它生成的資料越接近人類需求,它就越無縫地融入我們的世界。
瞭解世界的框架
為了駕馭這個不斷變化的格局,我相信要構建一個理解世界的認知框架——一個有助於將資訊組織成一個連貫結構的正規化。 這個概念與托馬斯·庫恩的《科學革命的結構》一致,他在《科學革命的結構》中介紹了正規化轉變的想法,即科學思想的非線性和顛覆性變化。 庫恩將正規化定義為科學界接受的集體世界觀。 同樣,我的個人世界觀是透過一個認知框架構建的,該框架幫助我系統地處理資訊,而不是混亂地處理資訊。
雖然我不贊同嚴格的決定論,但我堅信,有一個結構化的框架可以提高我們理解和管理世界的能力。 然而,這樣的框架不應該被誤認為是一套僵化的規則或形式化的理論——它是一個靈活、不斷發展的視角,它塑造了我解釋知識的方式。
波普爾、維特根斯坦和知識的極限
卡爾·波普爾的偽造理論仍然是一個爭論的話題,但我發現他的三個世界理論特別耐人尋味。 在《客觀知識:進化論》中,波普將現實分為三個不同的世界:
世界1:物理世界,由生物實體、物體和事件組成。
世界2:人類意識和感知的主觀世界。
世界3:客觀知識的世界,包括人類文化、理論和知識文物。
路德維希·維特根斯坦在他的《邏輯哲學論文》中引入了另一種觀點,將世界分為兩個領域:可言(可以用語言表達的東西)和不可言(超越語言表達的東西)——神秘主義的領域。 他著名的斷言「我語言的侷限性意味著我世界的侷限性」,深刻地影響了我的思維。
透過將波普爾和維特根斯坦的框架並列,我形成了一個主觀的觀點:將世界2和3與維特根斯坦的語言世界聯絡起來,同時將維特根斯坦的不可言喻的世界(Kant’s Thing本身)放在世界1之前。 認知科學家Donald Hoffman的介面感知理論(ITP)解釋說,基於量子物理學和進化生物學的發現,我們的感官引導我們走向促進有用行動的感知。 透過自然選擇,我們的感官感知不斷完善。 然而,在適應性和準確性(真理)之間往往存在權衡。由於這些限制,我們完全理解認知世界的能力本質上是有限的和有限的。
LLM的邊界:認知正規化中的新世界
2022年11月30日,OpenAI釋出了GPT-3.5的第一個版本,這是一個在大量文字資料集中訓練的模型,能夠識別和生成類似人類的語言。 其核心是,LLM在機率預測上操作——使用語言的高維向量表示來計算序列中最有可能的下一個單詞。 這從根本上將LLM與語言的時空性質聯絡起來,因為他們試圖將他們的輸出與人類認知模型保持一致。
有些人猜測,人工智慧最終將成為一個自主的代理人,塑造人類無法控制的社會、歷史和文化。 雖然我仍然對這種說法持懷疑態度,LLM的固有缺陷:幻覺——產生看似合理但事實不正確的資訊的傾向。 「人工智慧教父」傑弗裡·辛頓警告說,人工智慧能夠產生誤導性的文字和影象,可能會讓網際網路充斥著虛假資訊。 人工智慧構成的威脅不僅僅是生存——它還挑戰了文化穩定和智力完整性。
語言的侷限性和人工智慧的擴充套件
大多數LLM主要根據英語資料進行培訓,其中包含大約25萬個獨特的單詞。 當考慮這些單詞的所有可能排列時,組合的可能性是天文數字。 如果我們計算250,000階乘(250,000!),結果數字超出了傳統的計算,需要像斯特林公式這樣的對數近似值來估計。 這種驚人的複雜性表明,LLM在一個巨大但有限的語言邊界內運作——一個由機率決定的,而不是語義上無限的。
基於這個想法,我將LLM生成的人工智慧世界納入我的認知框架中。 透過在Popper模型中的世界2和世界3之間插入LLM,我得出了一個五層正規化:
世界1:難以言喻的世界(無數現實)。
世界2:生物實體、物體和事件的物理世界。
世界3:人類語言世界,由感知和認知塑造。
世界4:LLM生成的人工智慧世界,受計算機率支配。
世界5:客觀知識和智力文物的世界。
人工智慧、文化顛覆和知識的未來
人工智慧的真正危險不僅在於其欺騙的潛力,還在於其侵蝕原創性的能力。 隨著對LLM培訓資料需求的增長,我們面臨著迫在眉睫的危機:原始內容的枯竭。 人工智慧生成的文字和影象正在逐漸取代人類創造的內容,降低了對真實藝術和智力表達的激勵。 即使在物理世界中,3D列印也能實現無限複製,從而降低了手工物品的獨特性。
雖然LLM可能會變得更加精緻和具有成本效益,但其進步仍然具有內部競爭力,而不是對外擴張。 隨著人工智慧生成的內容成為知識生產的主要形式,它可能會阻礙人類對原創思想的驅動力。 這反過來又對世界5——客觀知識的世界構成了直接威脅,阻礙了其擴張,模糊了真相和捏造之間的界限。
人工智慧引起的「替代焦慮」的解藥在於培養人類的原創性。 透過儲存和鼓勵創造性的努力,我們維護人類知識的擴充套件,並保護定義我們集體智慧的文化結構。





發表留言